
HTTP (Hypertext Transfer Protocol) is an application layer protocol used for communication between computers and network systems. HTTP is basically the basis (protocol, rules) of client-server data communication for the World Wide Web (www) and is used to load web pages using hypertext links contained in web pages. A typical HTTP flow involves a client (usually a web browser) making a request to a server and then the server returning a response message.
Within the HTTP stream, the server and client communicate through request messages and responses that they send to each other. The messages sent by the client to retrieve a resource are called requests and the responses returned by the server to the request are called responses.
HTTP is not only used to retrieve hypertext documents. Thanks to its extensibility, it can be used to fetch images, videos, etc. and to transfer (post) the desired elements to the server. It can be used to update any form used in web pages and transfer the information to the server (post) or to update a part of the web page.
Importance Of Http In The Web And Internet Browsing
The importance of HTTP (HyperText Transfer Protocol) in the web and internet browsing is profound, serving as the backbone of data communication on the World Wide Web. Here are several key reasons why HTTP is crucial:
Universal Standard for Web Communication
- Foundation of Web Browsing: HTTP is the standard protocol for fetching resources on the web, such as HTML documents, images, and videos. Every time you visit a website, your browser uses HTTP to request web pages and display them.
Stateless Protocol Enabling Scalability
- Statelessness: HTTP is designed to be a stateless protocol, meaning each request from a client to a server is independent; the server does not retain session information. This statelessness simplifies the interaction between client and server, leading to easier scaling of web services because servers do not need to maintain session state for millions of users.
Facilitates Distributed, Collaborative Information Systems
- Flexibility and Integration: HTTP enables the integration of various types of information systems and supports distributed, collaborative environments by allowing diverse web resources to link to each other. This has led to the creation of the interconnected web as we know it, where resources from different sources can be seamlessly accessed and integrated.
Basis for Web Technologies and Development
- Platform for Web Technologies: Beyond basic web browsing, HTTP serves as the foundation for more complex web technologies and protocols, including web services and RESTful (Representational State Transfer) APIs, which are crucial for building modern web applications.
Secure Communication via HTTPS
- Security with HTTPS: While HTTP itself is not secure, its extension, HTTPS (HTTP Secure), adds a layer of security by encrypting the data transmitted between the client and server. This is critical for protecting sensitive information during transactions, making web browsing safer.
Enabler of Web Evolution and Innovation
- Evolution and Extensibility: HTTP has evolved over time (from HTTP/1.1 to HTTP/2 and now HTTP/3), with each version introducing improvements in efficiency, speed, and security. This adaptability has supported the continuous growth and complexity of web applications and services.
Essential for Internet Infrastructure
- Critical for Internet Infrastructure: HTTP's role extends beyond just web browsing; it is integral to the infrastructure of the internet, supporting cloud services, content delivery networks (CDNs), and more. It helps optimize the delivery of content and services across the globe.
In summary, HTTP is indispensable for the operation of the web and internet browsing, providing a flexible, scalable, and extendable protocol that underpins the vast majority of online communication and data exchange. Its evolution into more secure and efficient versions ensures its continued relevance in supporting the ever-expanding and innovating landscape of the internet.
What are the Basic HTTP Components?
While client server communication takes place in the HTTP flow, there are various basic components that take part in this flow and make up the flow. These are user-agent, proxy and web servers. Requests from the client to the web servers are forwarded through the user-agent or through proxies that act as a proxy secondary server between the client-agent and the server.
The typical client-agent is usually a web browser, i.e. a user's internet browser, but requests to a web server are not only forwarded from real user-agents. Bots (spiders) that crawl the web or various request-sending applications can also serve as user-agents.
Requests sent from the client (whether it is a real user user-agent or not) are forwarded to the relevant servers and the authorized servers return responses related to the requests. The request sent by the client can be forwarded from the server hosting the resources to another proxy server acting as a proxy and then to the main server. In such a scenario, the responses returned from the main server go to the proxy server before going to the client.
An example of a proxy server is cloudflare proxy servers.
Proxy servers take part in processes such as hiding the main servers for security purposes, accelerating client-server communication by caching requests and responses.
Client (User-Agent)
A user-agent is any application or agent that acts on behalf of a user. This role is usually performed by web browsers (browsers), but applications that can send various requests can also be clients by creating requests as user-agents.
In the client-server communication that takes place in the HTTP stream, browsers usually assume the role of user-agent on the client side and send a request to the server or a proxy server that acts as a proxy server of the server in order to access a web page on behalf of the client.
If the request is received by the proxy server, the request can be sent to the main server to access information about the web page from which the request was sent, or if a cache for the resource from which the request was sent is available on the proxy server, the cache is checked for currency and a response is returned.
If there is no cache on the proxy server, the request for the requested resource is forwarded to the main server. In the absence of a proxy server, client requests go directly to the main server where the web page is hosted. A wide variety of servers, such as DNS servers, play different roles in client-server communication, but basically this is the HTTP client (user-agent) - server data exchange model in simplified form.
The response containing the HTML document related to the web page requested by the client (user-agent) to be accessed is transmitted by the server to the web browser and the web browser parse (parse, process) the relevant resource and sends new requests related to the extra resources that make up the page.
On-page static resources such as CSS, JS, images, etc. that make up the requested web page are obtained through the HTTP request - response flow and the web page is created accordingly.
Important Note: HTTP 200 (OK) response code may not be returned for all web pages for which a request is sent to be accessed by the client. HTTP (500 and derivatives) response codes may be returned by the server if the requested resource has been redirected (301,302,307), deleted (HTTP 404,410) or if there is a server error.
Web Server (Web Servers)
The web server, which represents the other end of client-server communication, hosts and processes website-related resources and returns HTTP responses to HTTP requests from the client(s). The server that returns responses to HTTP requests may appear virtually as a single server in HTTP headers, but a load balancer server structure (a web server structure consisting of multiple servers that balance request loads) can also be used, which is a multi-server structure that distributes requests from the client.
It is possible to host the resources of a document to which an HTTP request is sent on multiple servers and to load the resources after the request by pulling them from different servers. One or more servers can render a single web page or specific parts of a web page.
Proxy (Proxy Servers)
In the client-server (the server hosting the resource from which the request is sent) communication process, a large number of intermediate servers (computers) are involved in the transmission of HTTP messages. At the application layer of the network connection between computers, the intermediate servers involved in HTTP streams are usually called proxies.
As intermediate servers, proxies can be involved in direct forwarding, filtering, authorizing, distributing the request load and caching requests from the client. Depending on their role, they can be explicitly displayed in HTTP headers or hidden.
How HTTP Works ? Classic HTTP Flow
When a client wants to communicate with a server, such as an intermediate (proxy) server that acts as an end server or a main server, it performs the following typical HTTP steps.
1 -TCP Connection
The first step in the HTTP flow is to establish a TCP connection between the client and the server. With a TCP connection, the client can send a request to the server and the server can send a response to the client and data exchange can take place. The client can establish multiple TCP connections or exchange data over a single TCP connection. The number and need for TCP connections varies according to the HTTP version used in client server communication.
2 - HTTP Request Message
Another step after the TCP connection is the transfer of the HTTP request message from the client to the server. The client transfers the HTTP message to the server for the action it wants to perform on the server side.
GET /what-is-dns/ HTTP/1.1
Host: techseohub.com
Scheme: https
User-Agent: Chrome Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
In an HTTP request example like the one above, the first line is the "request line". Here, the GET method indicating the purpose of the request, the path of the URL to be accessed (path) /what-is-dns/ and the HTTP version HTTP/1.1 to be used in the connection are specified.
The HTTP headers following the request line contain details about the request and connection. For example, the https expression used in the Scheme header indicates that the HTTP connection will be made over the secure protocol, that is, the secure version.
In the Accept-Encoding section below it, it is conveyed which compression methods are (will be) supported by the client in the responses to the HTTP request sent. For the example above, gzip, deflate and br are specified here. In accordance with this request header, the server can return a resource compressed with any of the 3 compression methods.
3 - HTTP Response Message
After the HTTP request message is transmitted to the server during the request phase of the HTTP connection, the server processes the HTTP information contained in the request and returns the appropriate response to the client.
In response to the above example HTTP request, the server returns a response to the client as in the following example.
HTTP/1.1 200 OK
Date: Sat, 01 Feb 2022 14:38:22 GMT
Server: Nginx
Last-Modified: Tue, 01 Jan 2022 21:58:32 GMT
ETag: "43214ad3-1568-555a123b2791c"
Accept-Ranges: bytes
Content-Length: 39769
Content-Type: text/html
A 39769 byte HTML document (Content) is sent under the HTTP Response headers.
In response to the HTTP request above, an HTTP response like this example can be returned from the server. The top part of this HTTP response example is the HTTP response line, which is the server side equivalent of the HTTP request line. In the first part of the HTTP response line, HTTP/1.1 is used to indicate that the response is based on the HTTP/1.1 version. The following 200 and OK messages convey the status code of the HTTP response and the information that the request was processed successfully with the OK message.
The HTTP headers following the response line also contain details about the response, caching and server. For example, Nginx, which is specified in the Server: header just below the response line, specifies the web server type of the main server or intermediate server (proxy) from which the response is returned. The Date: section provides the date and time when the response to the request was returned.
4 - In Progress HTTP Requests and Responses
After the initial TCP connection, the TCP connection can be terminated or the connection can continue after the HTTP request transmitted and the HTTP response received. The main factor here is whether the client needs different resources after the resource sent in the response to the HTTP request.
After any resource transmitted as an HTTP response, if the client needs a different resource from the resource, or if it transmits a request to reach another resource from the server (if it wants to transmit), the TCP connection continues or a new TCP connection is established.
In pre-HTTP/2 versions, since a separate TCP connection had to be established for each request and a request for the second resource could not be sent with the second TCP connection before the end of one connection, HTTP pipelining techniques were (are) used to overcome the congestion at the point of resource transfer. However, with the multiplexing technology introduced with HTTP/2, multiple requests can be sent and responded to using a single TCP connection, increasing the data exchange speed and ease of operation in HTTP/2 and later versions.
What are HTTP Messages?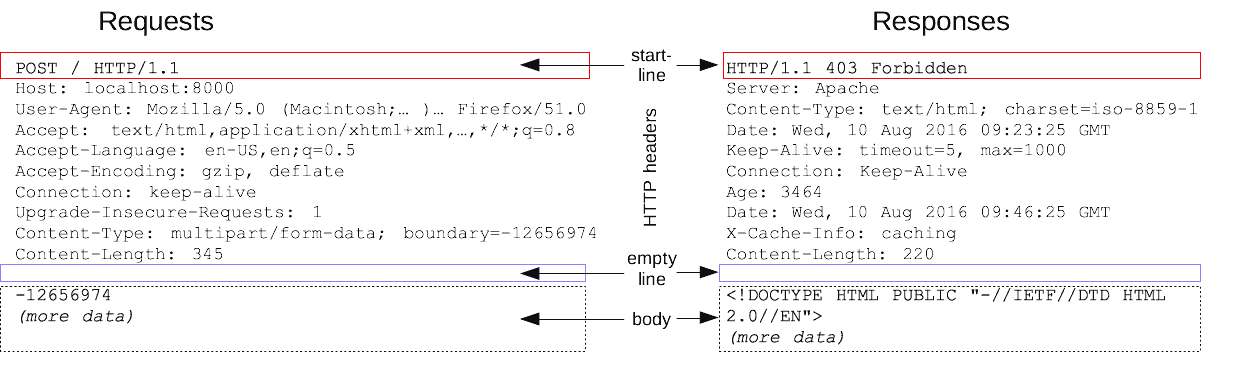
HTTP messages are the core means of communication between clients (e.g., web browsers) and servers on the World Wide Web. They are used to request web resources and deliver those resources from servers back to clients. HTTP messages come in two types: requests, sent from the client to the server, and responses, sent from the server back to the client. Both types of messages have a specific structure, consisting of a start-line, headers, an empty line, and an optional message body.
HTTP Request Messages
An HTTP request message is generated by a client to request a resource from a server. It consists of the following components:
- Request Line: This is the first line of the request message and includes three parts: the method (e.g., GET, POST), the request-target (usually the URL or URI of the resource), and the HTTP version (e.g., HTTP/1.1).
- Headers: Following the request line are HTTP headers, which provide additional information about the request. Headers can include things like the type of web browser making the request (User-Agent), the types of content that can be understood in response (Accept), and other request-specific details like cookies (Cookie).
- Empty Line: An empty line indicates the end of the headers section.
- Body (optional): The body of a request is not present in every HTTP request; it's typically used with methods like POST or PUT to send data to the server, such as form data or file uploads.
HTTP Response Messages
An HTTP response message is sent by a server in reply to a client's request. Its structure includes:
- Status Line: Similar to the request line but for responses, the status line includes the HTTP version, a status code (e.g., 200 OK, 404 Not Found), and a reason phrase that provides a textual description of the status code.
- Headers: Response headers convey additional details about the response, such as the type of content being sent (Content-Type), content length (Content-Length), and server information.
- Empty Line: This separates the headers from the body, just like in the request message.
- Body (optional): The body of a response contains the requested resource or data. This could be an HTML document, an image, JSON data for APIs, or any other type of content.
Importance of HTTP Messages
HTTP messages are fundamental to the operation of the web, allowing for the structured exchange of information between clients and servers. The request-response cycle facilitated by HTTP messages is what enables web browsers to retrieve web pages, submit form data, download files, and interact with web applications. The standardized format of these messages ensures interoperability and consistency across different web technologies and platforms.
What is HTTP Request?
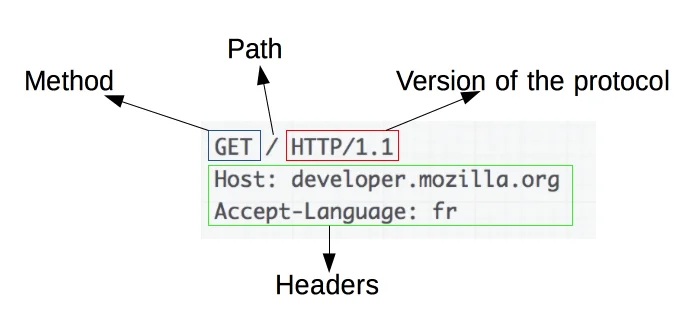
An HTTP request is a message sent by the client (user agent) to initiate an action on the server and to load the resources needed to access the requested resource.
HTTP request messages sent from the client are transmitted over the internet network to authorized, intermediary servers, encoded with data related to the scope of the request.
An HTTP request is composed of multiple components.
These are ;
- HTTP request line
- URL - The client uses the components of a URL that contain the information needed to make a request and access the resource. The components of a URL describe the resource to be accessed (URL Components: HTTP Schema (HTTP - HTTPS), Domain (Host), URL Path, Syntax (parameters))
- HTTP version (Ex: HTTP 1/1, 2 or 3)
- HTTP method (GET, POST etc.)
- HTTP request header
- HTTP Request Body - The HTTP request body is optional.
An example HTTP request line is as follows:
GET (Method) /hyper-text-transfer-protocol (Path) HTTP 1.1 (HTTP version)
What are HTTP Request Methods?
HTTP request methods are the name given to the methods used to specify the desired action to be performed (initiated) on the requested resource. The client transfers the action it wants to perform on the server to which the request is sent by using HTTP messages through methods. Depending on the HTTP request method(s) sent in a classic HTTP flow, the server usually returns an HTML document as request output to the client. The server does not always return an output depending on the HTTP request sent. The request sent from the client can be used to delete or update data on the server.
In HTTP 1.0 version, GET, POST and HEAD methods were first published. Subsequently, 5 new methods were added with HTTP 1.1. The added methods are PUT, DELETE, CONNECT, OPTIONS, and TRACE. There is no restriction on the number of methods that can be defined in HTTP methods.
A client can send any of these methods to a resource and the server can be configured to respond to any one or more of these HTTP methods. The server does not have to respond to and process all HTTP request methods sent. If the DELETE request sent to a resource is not configured on the server side, the request will fail and the server may return an error or blocking message in the HTTP response.
GET Method
The Get method is used to retrieve data and resources from the source from which the request was sent. The current state has no other purpose or function other than retrieving a copy of the requested data.
HEAD Method
Head method, unlike GET method, is the name given to the method used to retrieve metadata without a body from a resource to which the request is sent. Similar to the GET method, it is used to retrieve data from the source from which the request is sent, but the responses to this request do not contain HTTP body data.
POST Method
The post method is a request method used to register the resource in the sent request as a new sub-resource of the target URL by the server. With the post method, the resource specified in the request sent from the client (for example, a user comment) is transmitted to the target server and this resource is saved to the database, server and the relevant data is added to the site.
Examples of transactions using this method are; Shopping completion transactions on e-commerce sites, Form responses and forum, user comments.
PUT Method
The Put method is a request method used to update the status of the resource specified in the sent request at the destination URL or to create a record if there is no record of the relevant resource and to stock the resource at the specified URL. Unlike the post method, the PUT method specifies the final address (destination) of the resource sent to the server.
DELETE Method
Delete method is the method where the specified data for the target resource is requested to be deleted.
CONNECT Method
The Connect method is the method used to establish a TCP/IP tunnel to the source server defined by the request.
OPTIONS Method
The Options Method is the method used to retrieve the HTTP methods supported by the server to which the request is sent. It is used to measure the functionality of the server for HTTP requests.
TRACE Method
The Trace Method is a request method used by the server to request back the request sent by the client to which the request was sent. Using this method, it is possible to check whether the first sent request has been modified by intermediate servers.
PATCH Method
The Patch Method requests the target resource to change its state according to the partial update defined in the notation attached to the request. The Patch method allows the target resource to be partially updated as specified in the request. With this method, a part of a resource or document can be updated instead of requesting or updating the entire document. Thus, an advantage can be provided in terms of bandwith.
HTTP Request Headers
HTTP request headers are headers that follow the same basic structure of an HTTP header, passing details about HTTP requests to the destination server. The server to which the HTTP request is sent shapes the response using the information sent in the HTTP request headers.
For example, the accept header sent with the HTTP request is the header that conveys what will be accepted in the response from the server. The server shapes the response using the information in the accept: http request header.
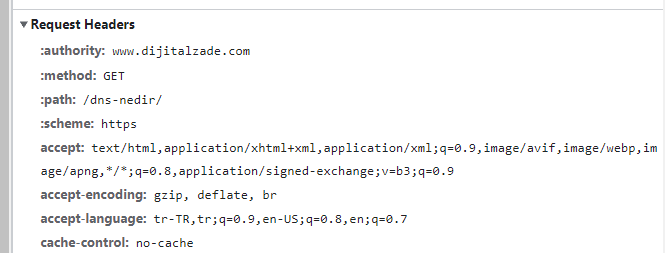
In the image above, you can view the header fields separated according to their functions in HTTP request headers and the request details transmitted by the client. The authority section in the HTTP request header displayed in the image is the section that specifies the host, that is, the target domain. The method section that follows is the section in which the method of the HTTP request is transmitted. The path section is the area where the target URL path to be requested from the target server transmitted in the HTTP request line is specified.

Not all headers under the Request section are called request headers. Some of the cache-control and similar header types mentioned in this section are header fields that perform tasks such as authorization, control, cache.
The headers that convey how and how the request is made are called request headers, while the general and representation headers transmitted with the HTTP request are called general and representation headers.
In the example image above, the headers marked in green are the header fields in the HTTP headers where the details and messages related to the HTTP connection independent of the request are transmitted. The headers in the blue section just below the relevant field are the sections where the details related to the HTTP message are transmitted.
Ex: In the above example, the Connection: keep-alive section in the section colored in green is the section where the data about how the TCP connection will be made and how the connection should continue is transmitted. It is independent of the HTTP request and the response from the server.
How to View HTTP Request Headers?
To view the HTTP request headers sent after any HTTP connection, the network sections in the developer tools sections of the browsers can be used.
For example: You can open the Chrome Devtools tool by pressing f12 while the Chrome browser is open and you can view the details of the HTTP request sent from the client and the details of the HTTP response sent from the server by selecting the HTML document from the network section on the opened panel.
You can view details about all the resources used in an HTTP data exchange from the network area in the dev tools section of the browsers.
HTTP Request Body
The final part of the HTTP request is the HTTP Body, the HTTP request body. In the HTTP Body section, data related to the request sent and the change to be made on the server are transferred.
Not all HTTP requests are sent to the target server with the body section full. Generally, in requests such as GET, HEAD, DELETE, the body section is not needed since no variable data is sent to the server.
In requests such as PUT, PATCH, etc., the request is sent to the server with the HTTP request body section full and the server is expected to update and process according to the data from the body. In PUT requests, the HTTP body section usually sends update data related to a change made on the site via the client.
What is HTTP Response?
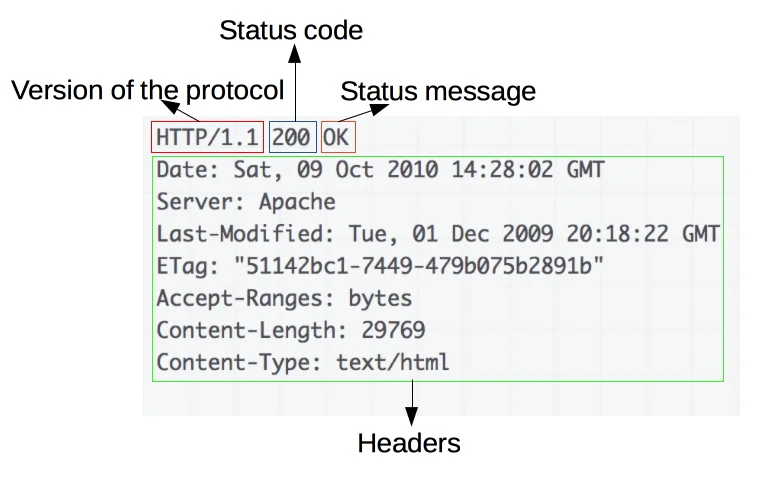
HTTP Response is the response that a client (usually browsers) receives from a destination or intermediate server in response to an HTTP request. Depending on the data transmitted with the HTTP request sent, the HTTP response generated by the server transmits the data corresponding to the incoming HTTP request to the client.
A typical HTTP response consists of the following components;
- HTTP response line (HTTP response line) Ex: In the image above, HTTP/1.1 200 OK is the HTTP response line.
- version of the HTTP protocol
- HTTP response code (200,301,404,500 etc.) (HTTP Status code)
- HTTP response code message (HTTP status message)
- HTTP response headers (similar to request headers)
- HTTP response body, which contains data about the source from which the request is sent, depending on the situation
HTTP Response (Status) Codes
HTTP response (status) codes are the name given to the response (reply) codes returned by the server to an HTTP request sent by the client. "In HTTP/1.0 and later, the first line of the HTTP response is called the status line and contains a numeric status code (such as "404") and a textual reason phrase (such as "Not Found")."
The server returns the server-side response of the HTTP requests received after the HTTP connection is established with a 3 digit response code and a written response, allowing the client to have information about the request sent. According to the response code received from the server, the user-agent processes the response and transfers it to the user.
The first digit of the response code can be used to determine which group the response belongs to. If a response code is returned by the server that the client does not know the equivalent of, the client will use the first digit of the response code to try to figure out what type of response it is.
HTTP response codes are divided into 5 according to their first digit and the messages they carry. HTTP 1xx, 2xx, 3xx, 4xx, 5xx.
- 1XX (100 Code Responses): 1xx HTTP Status codes are responses that indicate that the user's request is in progress on the server side. For example, an HTTP 100 response indicates that the request is currently being processed. This response is transmitted to the browser but is not reflected on the user screen.
- 2xx (200 Coded Responses): 2xx HTTP Status codes are responses sent from the browser to the server for the page, indicating that the operation was successful. HTTP 2xx responses indicate that the server responded successfully to the request from the browser and that the page can be opened. For example, in http 200 "OK" responses, the page is clearly visible in the user's browser after the request.
- 3xx (300 Coded Responses): 3xx HTTP status codes are responses that indicate that the request from the browser to the server for the web page is redirected to a different page. In other words, when a request is sent from the browser for pages with 3xx status codes, the server notifies that the relevant page is redirected to a different page with HTTP 3xx coded responses and redirects the user to the new page.
- 4xx (400 Coded Responses): 4xx HTTP status codes are responses that indicate that a user error has occurred. In other words, when a response with HTTP error code 4xx is sent to the browser, it is reported that the source of the error is the client, that is, the user. However, the user here should not be perceived only as the person who sends the request from the browser. HTTP error codes 4xx can occur after any operation applied on the site hosting the web page.
- 5xx (500 Code Responses): 5xx HTTP status codes are responses that indicate that a server error occurred during the request sent from the browser.
HTTP Response Headers
HTTP response headers, like HTTP request headers, follow HTTP header standards and contain information about server responses to HTTP requests. The client (user-agent) that sends the HTTP request processes and transfers the incoming data to the user according to the HTTP response and response headers received from the server.
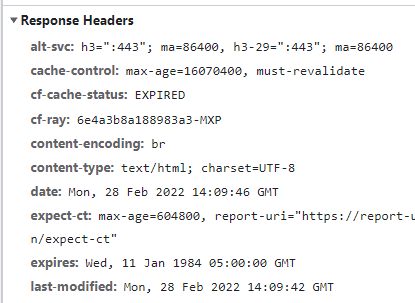
Chrome browser HTTP response header example
In the image above, you can see sample response headers from the network section of the Chrome browser.
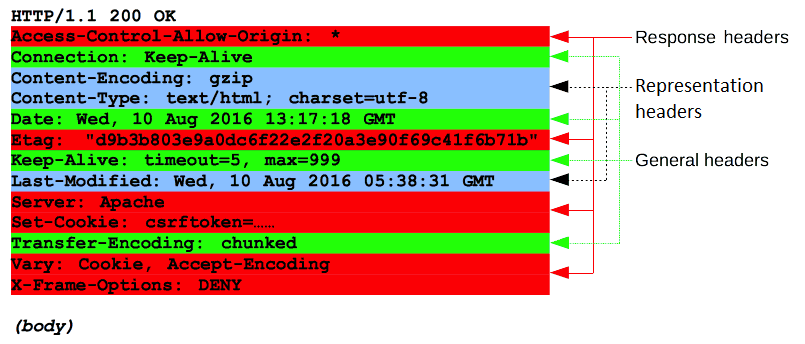
HTTP response headers sections Image-Source: developer-mozilla.org
As we mentioned in the HTTP request headers section above, not all headers used in HTTP response headers are directly related to the response. There are different headers that can be displayed in HTTP response headers other than the headers that are directly related to the response.
These headers are divided into several groups;
- General: These are headers that are independent of the response and contain general information about the HTTP connection.
- Response Headers: Headers that contain direct information about the HTTP response and the server. For example: Vary, Accept-ranges etc.
- Representation Headers: These are the headers that specify the data and information related to the HTTP messages transmitted.
As you can see in the colored sample HTTP response headers image above, in a sample HTTP response, in addition to the headers directly related to the HTTP response and the server, there are many general and representative headers that contain information about the HTTP connection and messages.
How to View HTTP Response Headers?
HTTP response headers can be viewed by using the network field in the developer tools sections of the internet browsers in the same way as the method of viewing HTTP request headers.
For this, in Chrome or Firefox tool, respectively ;
Press F12 after opening the page to send the request
Then click on the network section on the screen that opens
In the network area that opens, click on all
In the last section, all, you can look at the HTTP response headers by selecting the response (usually HTML) returned from the server.
HTTP Response Body
The final part of HTTP responses is the HTTP Body, the HTTP response body. As with HTTP requests, not all HTTP responses have to have an HTTP body. In the case of responses that do not require any loading in response to HTTP requests, the HTTP body is usually not sent. An example of such responses is (HTTP 201 Created).
Secure HTTP: HTTPS
HTTPS (HyperText Transfer Protocol Secure) is an extension of HTTP that is used for secure communication over a computer network, most notably the internet. HTTPS provides a layer of encryption that ensures the integrity and confidentiality of the data being exchanged between the client and the server. This added layer of security is essential for protecting sensitive transactions and communications, such as online banking, shopping, and any form where personal information is exchanged. Here's a deeper look into HTTPS and its significance:
How HTTPS Works
HTTPS integrates HTTP with a cryptographic protocol, typically SSL (Secure Sockets Layer) or TLS (Transport Layer Security), to encrypt the data. This process involves:
- Encryption: Encrypting the data ensures that any information exchanged between the client and the server cannot be read or tampered with by anyone intercepting the communication. This protects against eavesdropping and man-in-the-middle attacks.
- Authentication: HTTPS also involves the server presenting a digital certificate to the client. This certificate, issued by a trusted Certificate Authority (CA), verifies the identity of the server to the client, ensuring that the client is communicating with the genuine server and not an imposter.
- Data Integrity: Encryption also ensures that the data cannot be modified without detection during transmission, maintaining the integrity of the information being exchanged.
Components of HTTPS
- SSL/TLS Protocol: These protocols are used to encrypt the communication. TLS is the successor to SSL and provides stronger encryption algorithms and better security.
- Digital Certificates: Serve as the backbone of HTTPS's trust model. A digital certificate is a form of identification for the server, containing the server's public key and the signature of a Certificate Authority (CA) that has verified the server's identity.
- Secure Port: HTTPS typically runs on port 443, in contrast to HTTP, which runs on port 80.
Benefits of HTTPS
- Security: The primary benefit of HTTPS is the enhanced security it provides. Encryption protects the data from being intercepted and read by unauthorized parties.
- Trust: Websites using HTTPS display a padlock icon in the browser's address bar, signaling to users that their connection is secure. This builds trust, especially important for websites handling sensitive transactions.
- SEO Advantage: Search engines like Google give preference to HTTPS websites, considering it a factor for higher ranking in search results.
- Compliance: For certain regulatory requirements, such as GDPR in Europe, using HTTPS is part of complying with data protection and privacy laws.
Implementing HTTPS
Implementing HTTPS on a website involves obtaining a digital certificate from a Certificate Authority (CA) and installing it on the web server. Website administrators must also configure their servers to use the SSL/TLS protocols for secure communication.
In conclusion, HTTPS plays a critical role in securing the web by protecting the privacy and integrity of the information exchanged between clients and servers. Its use has become a standard best practice for all websites, not just those handling sensitive transactions, contributing to a safer and more secure internet.
HTTP/2 and HTTP/3
HTTP/2 and HTTP/3 are major revisions of the Hypertext Transfer Protocol (HTTP), designed to improve the speed, efficiency, and security of data transfer over the web. Below is a detailed look at both protocols:
HTTP/2
- HTTP/2 was standardized in May 2015 as RFC 7540.
- It is the second major version of the HTTP network protocol, used by the World Wide Web.
- Developed by the HTTP Working Group of the Internet Engineering Task Force (IETF).
- Designed to address some performance limitations of HTTP/1.x.
Key Features of HTTP/2
- Binary Framing Layer: Unlike the textual nature of HTTP/1.x, HTTP/2 introduces a binary framing mechanism that allows for more efficient parsing and multiplexing of requests and responses.
- Multiplexing: Multiple requests and responses can be sent in parallel over a single TCP connection, significantly reducing the latency caused by HTTP/1.x's head-of-line blocking issue.
- Server Push: Servers can send resources to the client proactively, before the client requests them, improving load times for certain web pages.
- Header Compression: HTTP/2 uses HPACK compression format to reduce overhead.
- Stream Prioritization: Allows clients to prioritize requests, enabling more important resources to be sent first.
Benefits of HTTP/2
- Improved page load times due to reduced latency.
- Reduced connection overhead through compression and multiplexing.
- Better utilization of underlying TCP connection.
- Enhanced user experience on websites and web applications.
HTTP/3
- HTTP/3 is the third and latest major version of the HTTP protocol, defined by RFC 9114.
- It is built on top of QUIC (Quick UDP Internet Connections), which is a transport layer network protocol developed initially by Google.
- QUIC operates over UDP (User Datagram Protocol) instead of TCP, which is used by both HTTP/1.x and HTTP/2.
Key Features of HTTP/3
- QUIC Protocol: Offers reduced connection and transport latency, and better congestion control compared to TCP.
- Built-in Encryption: QUIC integrates TLS 1.3 encryption, enhancing security and privacy.
- Connection Migration: Supports changing network interfaces without interrupting the connection, beneficial for mobile devices.
- Stream Multiplexing Without Head-of-Line Blocking: Similar to HTTP/2 but without TCP’s head-of-line blocking, as QUIC handles packet loss more efficiently.
Benefits of HTTP/3
- Faster connection times and reduced latency.
- Improved performance in conditions of packet loss and network changes.
- Enhanced security through mandatory encryption.
- More efficient handling of multiple simultaneous streams.
Transitioning from HTTP/2 to HTTP/3
- Adoption of HTTP/3 is growing, but the transition requires support from both client (browsers) and server software.
- Major browsers and many large web services have started supporting HTTP/3.
- The choice between HTTP/2 and HTTP/3 may depend on specific network conditions and compatibility considerations.
Conclusion
The journey through the world of HTTP has unveiled the pivotal role this foundational protocol plays in the fabric of the internet and web browsing. From its humble beginnings as a simple mechanism for retrieving hypertext documents to its current iterations in HTTP/2 and HTTP/3, HTTP has evolved to meet the ever-growing demands for speed, efficiency, and security in the digital age. This evolution highlights not just technological advancement but also a commitment to creating a more connected and secure internet.
HTTP's universal standardization as the lingua franca for web communication underscores its importance in facilitating the seamless flow of information across the globe. The protocol's design principles, such as statelessness and extensibility, have ensured that it remains scalable and adaptable to the vast and varied needs of the modern web. Moreover, the advent of HTTPS has addressed the critical need for secure communication, protecting users' data from prying eyes and building trust in online transactions.
As we look towards the future, the adoption of HTTP/2 and HTTP/3 promises even greater improvements in web performance and user experience. These versions introduce significant enhancements, such as multiplexing, server push, and built-in encryption, which are set to redefine the efficiency of web communications further. The transition to these newer protocols, while gradual, marks a significant step forward in the quest for a faster, more secure, and more reliable web.
In conclusion, HTTP stands not just as a protocol but as a cornerstone of the World Wide Web. Its continuous evolution reflects the dynamic nature of the internet, adapting to the challenges and opportunities that come with the digital era. As we navigate the complexities of the web, understanding HTTP and its development is crucial for anyone looking to grasp the intricacies of internet technology and its impact on our digital lives. The story of HTTP is far from over, and its future iterations will undoubtedly continue to shape the internet in ways we can only begin to imagine.
This exploration of HTTP, from its basic components to the latest developments in secure and efficient web communication, offers a comprehensive overview of a protocol that powers our daily internet experiences. As the web continues to evolve, so too will HTTP, ensuring that it remains at the heart of digital innovation and connectivity.
